Ограничения машинного обучения в NLP/NLU
Недавно Джастин Ли опубликовал статью “Chatbots were the next big thing: what happened?”, в которой он рассуждает о том, почему чат-боты до сих пор не заменили мобильные приложения, и чего ожидать от чат-ботов в будущем. Один из тезисов данной статьи: NLP только начинает выходить за пределы исследовательских лабораторий и работает пока не достаточно хорошо. Поскольку сейчас в NLP используется в основном машинное обучение, давайте попробуем разобраться более конкретно, насколько хорошо машинное обучение работает в NLP/NLU, и какие фундаментальные ограничения существуют в этой области на данный момент.
Рассмотрим современные модели классификации текста. Это могут быть, к примеру, сверточные нейронные сети или LSTM. Что они “выучивают” при машинном обучении? Конечно, эти модели на самом деле не “понимают” смысла слов и предложений, как понимает их человек. Можно сказать, что нейронные сети “выучивают” паттерны, которые статистически связаны с определенным классом. Поскольку сейчас повсеместно используются векторные представления слов, данные паттерны не являются просто весами определенного слова или n-граммы в тексте, как это было при использовании более простых линейных моделей. Эти паттерны являются скорее паттернами диапазонов координат слов и комбинаций слов в векторном пространстве. Это позволяет, например, распознавать паттерны даже при замене слов на близкие по смыслу. Кроме того, некоторые модели, например LSTM, теоретически могут “выучивать” паттерны переменной длины. Все это, конечно, делает современные нейронные сети более эффективными и “умными” для NLP по сравнению с используемыми ранее моделями или алгоритмами на основе ключевых слов. Однако, для создания моделей, полноценно понимающих естественный язык, остается множество фундаментальных ограничений. Попробуем систематизировать эти ограничения.
Контекст
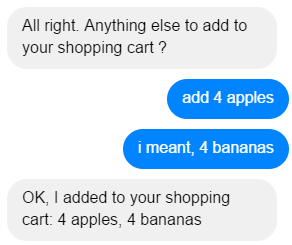
Про проблему контекста говорят многие. Существуют различные подходы к решению данной проблемы при создании чат-ботов. Однако, в большинстве случаев проблему контекста понимают слишком узко. Обычно под контекстом понимают информацию из предыдущих сообщений пользователя. Но понятие контекста гораздо шире. Смысл одной и то же фразы может меняться в зависимости от того, кто, когда, каким тоном и при каких обстоятельствах данную фразу произнес. В таком широком смысле чат-боты не понимают контекста сообщений пользователя. Можно попробовать подойти к решению данной проблемы различными способами. Например, передавать данные о пользователе как фичи в модель, передавать предшествующее поведение пользователя на сайте или в приложении в модель и т.д. Однако, это достаточно сложно и все равно не позволит в полной мере решить проблему контекста.
Concept Drift
Понятие concept drift в машинном обучении означает, что статистические свойства данных могут меняться с течением времени. Concept drift встречается в NLP-задачах. Язык постоянно изменяется, появляются новые слова, выражения и т.д.. Точность моделей машинного обучения будет деградировать со временем. Существуют различные подходы к решению данной проблемы. Одним из способов является дообучение или переобучение моделей в продакшене. Этот подход работает не всегда, т.к. характер распределения данных тоже может меняться со временем, а архитектура и гиперпараметры моделей могут быть затюнены для текущих данных. Каким образом создавать чат-ботов, который будут подстраиваться под изменчивый сленг, пока до конца не ясно.
Reasoning
Допустим чат-бот для бронирования билетов получит такое сообщение:
Забронируй столько билетов до Лондона, сколько пальцев на руке
С этой задачей справится любой живой человек. Даже ребенок знает сколько пальцев на руке. Но чат-бот будет, скорее всего, бессилен в решении данной простой задачи (если только автор специально не предусмотрит конкретно эту ситуацию). Чат-боты на основе машинного обучения способны распознавать определенные сложные паттерны в тексте, но они не способны провести простейшее рассуждение, вывести какой-либо результат из задачи и имеющихся фактов и затем использовать его в дальнейшей работе. Да, существуют нейронные сети, которые отвечают на вопросы по картинке. Но, во-первых, данные модели весьма ограничены в своих возможностях. Во-вторых, они все равно не осуществляют reasoning как таковой.
Вообще, одним из популярных аргументов критиков машинного обучения из других областей AI является отсутствие ясного понимая того, как реализовать reasoning при помощи машинного обучения. Хотя такие попытки делаются.
Выводы
Современные нейронные сети являются более эффективными и “умными” моделями для NLP по сравнению с линейными моделями или алгоритмами на основе ключевых слов. Однако, для создания систем, полноценно понимающих естественный язык, на данный момент существует множество фундаментальных ограничений. Тем не менее, машинное обучение является отличным инструментом для решения многих практических задач в NLP/NLU.