Архитектура чат-ботов с обработкой естественного языка
В данной статье я попробую систематизировать современные подходы и собственный опыт построения чат-ботов, ориентированных на выполнение специализированных задач, формулируемых пользователями на естественном языке. Как правило, такие чат-боты представляют собой гибридные системы, объединяющие модели машинного обучения, классические алгоритмы и движки правил. Как они устроены?
Если обобщить находящуюся в публичном доступе информацию [1, 2, 3, …] и собственный опыт проектирования чат-ботов, структуру бота можно примерно изобразить следующим образом:
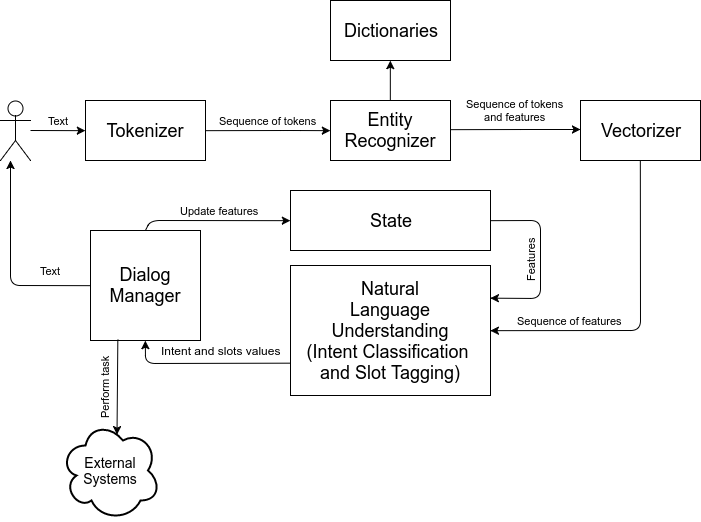
Разберем устройство каждого блока. Итак, сначала текст пользователя преобразуется в последовательность токенов при помощи токенизатора (tokenizer). Как правило, токенизаторы разбивают текст на отдельные слова.
Допустим, мы создаем бота, который позволяет искать информацию о фьючерсах и курсах валют. Пользователь пишет сообщение: “Найди мне цены нефтяных фьючерсов WTI на январь!!!”. Токинизатор разделит данную фразу следующим образом:
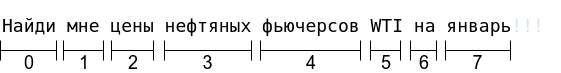
Далее последовательность токенов передается в компонент распознавания сущностей (entity recognizer), который распознает отдельные токены или N-граммы токенов как сущности (entity). Типы распознаваемых сущностей зависят от задач, которые выполняет чат-бот. Это могут быть имена, названия, коды, обозначения валют, серийные номера и т.д. Для распознавания сущностей используются, как правило, классические алгоритмы: поиск по словарям, регулярные выражения, ключевые слова и т.д. Компонент распознавания сущностей генерирует последовательность тегов, которые маркируют токены. Зачем предварительно распознавать сущности при помощи обычного поиска, если мы собираемся применить машинное обучение? На это есть несколько причин:
- в обучающем наборе данных могут быть представлены не все возможные сущности;
- создание датасета со всеми возможными комбинациями сущностей может быть непрактичным;
- данный подход позволяет добавлять новые сущности без переобучения моделей.
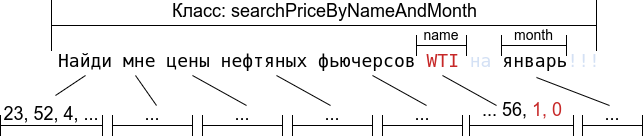
В примере выше название марки нефти WTI является сущностью, которую чат-бот мог бы распознать, используя таблицу наименований фьючерсов. Исходная последовательность токенов была бы промаркирована следующей последовательностью тегов:

Где 0 – токен не относится к сущности, name – токен относится к названию фьючерса.
Затем последовательность токенов и тегов передается в векторизатор (vectorizer). Векторизатор преобразует отдельные слова в числовые последовательности (векторные представления). Для этого могут использоваться модели Word2Vec, GLOVE или FastText, предобученные на больших корпусах текстов. Однако, если задачи бота узкоспециализированные, и имеется большой набор данных для обучения, то могут использоваться и самостоятельно обученные модели. Перед преобразованием в вектора обычно осуществляется простейший препроцессинг: удаляются стоп-слова, используется стемминг и т.д. После преобразования к векторам добавляются признаки тегов сущностей.

Затем последовательность векторов передается в компонент понимания естественного языка (natural language understanding – NLU) и комбинируется с текущим состоянием диалога (если до этого пользователь писал какие-либо сообщения, то текущая фраза уже должна рассматриваться в контексте) [4]. NLU выполняет две подзадачи:
- идентификация задачи, которую хочет выполнить пользователь (intent classification);
- выделение параметров задачи из сообщения пользователя (slot tagging).
Первая задача является задачей классификации. Вторая – задачей преобразования последовательности (seq2seq). Как правило, данные подзадачи решаются при помощи моделей машинного обучения. Может использоваться одна комбинированная нейронная сеть для решения двух задач одновременно, либо отдельная нейросеть для классификации задач и свой slot tagger для каждой задачи. Единственного универсального варианта реализации NLU не существует. Если задача определяется в большинстве случаев комбинацией представленных слотов (например, необходимо различать несколько видов поиска по различным параметрам), то с большей долей вероятности комбинированная модель покажет лучший результат. Если класс задачи в меньшей степени зависит от слотов, то стоит рассмотреть вариант с отдельными моделями.
Также существует множество вариантов архитектур моделей, котрые можно использовать для классификации и теггинга. Можно использовать двунаправленный LSTM, GRU, CNN, СNN с Gated Linear Unit [5], Q-RNN [6] и т.д. Помните, no free lunch [7]!
Допустим, фраза из нашего примера должна запускать задачу findPriceByNameAndMonth. Эта задача имеет два слота: name и month. Допустим, классификатор и теггер слотов корректно определили данную задачу и слоты:
Теперь класс задачи и значения слотов передаются в менеджер диалогов (dialog manager). Менеджер диалогов запускает задачи, вызывая API внешних систем, обновляет текущее состояние (state) и управляет ведением диалога с пользователем. Политика ведения диалога может быть реализована при помощи жестко описанного алгоритма, движка правил или модели машинного обучения. Зачем такие сложности? В приведенном выше примере все действительно просто: в одной фразе пользователя содержится указание на задачу и значения всех слотов для нее. Но что, если пользователь не укажет информацию для всех необходимых слотов? Тогда необходимо добавить чат-боту способность задавать уточняющие вопросы. Но что, если затруднительно точно определить, какую задачу имел в виду пользователь, и существует несколько вариантов того, какие именно слоты были пропущены? Поведение менеджера диалогов в данном случае может определятся моделью машинного обучения, а может программироваться при помощи правил.
Для того, чтобы сохранять контекст и информацию из предыдущих сообщений пользователя, менеджер диалогов обновляет состояние. Это состояние используется в NLU для того, чтобы учитывать контекст при классификации задач и теггинге слотов. Управление состоянием – достаточно сложная составляющая менеджера диалогов. Например, необходимо учитывать, что пользователь может “передумать” и потребовать выполнить другую задачу. Или потребовать выполнить другую задачу, но со слотами из предыдущей задачи.
Также менеджер диалогов отвечает за генерацию ответов пользователя. Для этого могут использоваться простые шаблоны, а могут и генеративные модели.
Заключение
Чат-боты с обработкой естественного языка, ориентированные на выполнение определенных задач, представляют собой достаточно сложные гибридные системы, объединяющие модели машинного обучения, классические алгоритмы и движки правил. В данной статье рассмотрен общий подход к построению подобных систем, не касаясь деталей реализации, обучения нейронных сетей, обеспечения масштабируемости, интеграции с внешними системами и т.д.
Даже рассматривая архитектуру чат-ботов с NLP на высоком уровне, можно сделать вывод, что разработка собственного специализированного чат-бота может потребовать исследования и решения достаточно сложных задач. Это зависит во многом от того, насколько сложны и специализированы задания, выполняемые ботом, и как они формулируются пользователями.
Ссылки:
- Spoken Dialog Systems – Task Oriented Systems
- Как устроена Алиса. Лекция Яндекса
- True Natural Language Understanding through a Conceptual Language Understanding Engine
- Easy contextual intent prediction and slot detection
- Language Modeling with Gated Convolutional Networks (arXiv:1612.08083)
- Quasi-Recurrent Neural Networks (arXiv:1611.01576)
- No free lunch theorem